

一、基本概念
1.编码
计算机要处理的数据除了数值数据以外,还有各类符号、图形、图像和声音等非数值数据。而计算机只能识别两个数字。要使计算机能处理这些信息,首先必须将各类信息转换成0和1表示的代码,这一过程称为编码。
2.数据
能被计算机接受和处理的符号的集合都称为数据。
3.比特
比特(Bit,二进制数位)是指1位二进制的数码(即0或1).比特是计算机中表示信息的数据编码的最小单位。
4.字节
字节表示被处理的一组连续的二进制数字。通常用8位二进制数字表示一个字节,即一个字节有8个比特组成。 1Byte= 8bit
字节是存储系统的最小存取单位。
二、字符表示
字符是人与计算机之间交互过程中不可缺少的重要信息。要使计算机能处理、存储字符信息,首先必须用二进制0和1代码对字符进行编码。
三、ASCII码
ASCII 码对英语字符与二进制位之间的关系,做了统一规定。
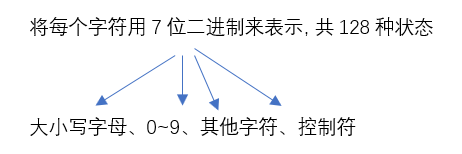
ASCII码是由美国国家标准委员会制定的一种包括数字、字母、通用符号和控制符号在内的字符编码集,称为美国国家信息交换标准码(American Standard Code for Information Interchange)。ASCII码是一种7位二进制编码,能表示27=128种国际上最通用的西文字符。是目前计算机中,特别是微型计算机中使用最普遍的字符编码集。
“0” —–48
“A” —–65
“a” —–97
ASCII 编码包括4类最常用的字符。
- 数字“0”~“9” 。ASCII编码的值分别为0110000 B ~ 0111001 B,对应十六进制数为30H~39H。
- 26个英文字母。大写字母”A”~”Z”的ASCII编码值为41H~5AH,小写字母“a”~“z”的ASCII编码值为61H和7AH。
- 通用符号。如“+” “-” “=” “*” 和 “/” 等32个。
- 控制符号。 如空格符和回车符等共34个。
ASCII码是一种7位编码,它存储时必须占一个字节,即8位: b7、b6、b5、b4、b3、b2、b1、b0。其中,b7恒为0,其余几位为ASCII码。
人们可以通过键盘输入和显示器显示不同的字符,但在计算机中,所有信息都是用二进制代码表示。n位二进制代码能表示2n个不同的字符,这些字符的不同组合就可以表示不同的信息。为使计算机使用的数据能共享和传递,必须对字符进行统一的编码。ASCII码是使用最广泛的一种编码。ASCII码由基本的ASCII码和扩充的ASCII码组成。在ASCII码中,把二进制位最高位为0的数字都称为基本的ASCII码。其范围是0~127;把二进制位最高位为1的数字都称为扩展的ASCII码,其范围是128~255。
补充:内码和外码
**内码:**对于计算机的文本文件,机器是存储其相应的字符的ASCII码(用一个ASCII码存储一个字符需8个二进制位,即一个字节,这些可被计算机内部进行存储和运算的数字代码称为内码。如输入字符“A” ,计算机将其转换成内码65后存于内存。
**外码:**计算机与人进行交换的字形符号称为外码,如字符“A”的外码是“A”。
通常一个西文字符占一个字节(半角),一个中文字符占两个字节。
| 十进制 | 十六进制 | 图形 |
|---|---|---|
| 32 | 20 | 空格 |
| 33 | 21 | ! |
| 34 | 22 | “ |
| 35 | 23 | # |
| 36 | 24 | $ |
| 37 | 25 | % |
| 38 | 26 | & |
| 39 | 27 | ‘ |
| 40 | 28 | ( |
| 41 | 29 | ) |
| 42 | 2A | * |
| 43 | 2B | + |
| 44 | 2C | , |
| 45 | 2D | – |
| 46 | 2E | . |
| 47 | 2F | / |
| 48 | 30 | 0 |
| 49 | 31 | 1 |
| 50 | 32 | 2 |
| 51 | 33 | 3 |
| 52 | 34 | 4 |
| 53 | 35 | 5 |
| 54 | 36 | 6 |
| 55 | 37 | 7 |
| 56 | 38 | 8 |
| 57 | 39 | 9 |
| 58 | 3A | : |
| 59 | 3B | ; |
| 60 | 3C | < |
| 61 | 3D | = |
| 62 | 3E | > |
| 63 | 3F | ? |
| 十进制 | 十六进制 | 图形 |
|---|---|---|
| 64 | 40 | @ |
| 65 | 41 | A |
| 66 | 42 | B |
| 67 | 43 | C |
| 68 | 44 | D |
| 69 | 45 | E |
| 70 | 46 | F |
| 71 | 47 | G |
| 72 | 48 | H |
| 73 | 49 | I |
| 74 | 4A | J |
| 75 | 4B | K |
| 76 | 4C | L |
| 77 | 4D | M |
| 78 | 4E | N |
| 79 | 4F | O |
| 80 | 50 | P |
| 81 | 51 | Q |
| 82 | 52 | R |
| 83 | 53 | S |
| 84 | 54 | T |
| 85 | 55 | U |
| 86 | 56 | V |
| 87 | 57 | W |
| 88 | 58 | X |
| 89 | 59 | Y |
| 90 | 5A | Z |
| 91 | 5B | [ |
| 92 | 5C | \ |
| 93 | 5D | ] |
| 94 | 5E | ^ |
| 95 | 5F | _ |
| 十进制 | 十六进制 | 图形 |
|---|---|---|
| 96 | 60 | ` |
| 97 | 61 | a |
| 98 | 62 | b |
| 99 | 63 | c |
| 100 | 64 | d |
| 101 | 65 | e |
| 102 | 66 | f |
| 103 | 67 | g |
| 104 | 68 | h |
| 105 | 69 | i |
| 106 | 6A | j |
| 107 | 6B | k |
| 108 | 6C | l |
| 109 | 6D | m |
| 110 | 6E | n |
| 111 | 6F | o |
| 112 | 70 | p |
| 113 | 71 | q |
| 114 | 72 | r |
| 115 | 73 | s |
| 116 | 74 | t |
| 117 | 75 | u |
| 118 | 76 | v |
| 119 | 77 | w |
| 120 | 78 | x |
| 121 | 79 | y |
| 122 | 7A | z |
| 123 | 7B | { |
| 124 | 7C | | |
| 125 | 7D | } |
| 126 | 7E | ~ |
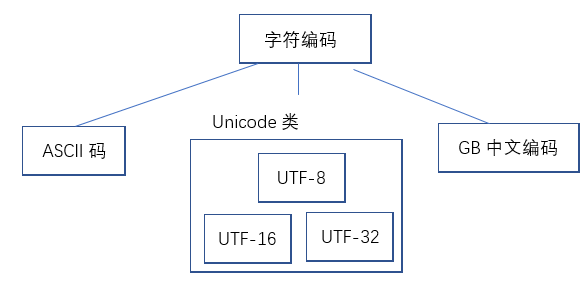
四、Unicode编码
世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码,因此Unicode应运而生。
Unicode,就像它的名字都表示的,这是一种所有符号的编码,将世界上所有的符号都纳入其中,每一个符号都给予一个独一无二的编码。
Unicode存在的问题:
Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。 如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费。
为了解决这个问题:就有了Unicode 三种实现:UTF8 UTF16 UTF32
UTF8可以方便的转换为UTF16和UTF32
UTF-8:,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-16:UTF-16 使用二或四个字节为每个字符编码(定长 一般情况下为2字节),因为对于绝大部分字符只使用2个字节就可以表示了。对于汉字而言,大部分汉字采用两个字节编码,少量不常用汉字采用四个字节编码。
**UTF-32:**UTF-32 使用四个字节为每个字符编码,使得 UTF-32 占用空间通常会是其它编码的二到四倍。UTF-32 与 UTF-16 一样有大尾序和小尾序之别,编码前会放置 U+0000FEFF 或 U+0000FFFE 以区分。
五、汉字信息编码
1. 汉字交换码
汉字交换码是指不同的汉字处理功能的计算机系统之间在交换汉字信息时所使用的的代码标准。自国家标准GB-2312公布以来,我国一直延用该标准所规定的国标码作为统一的汉字信息交换码GB5007-85图形字符编码。
GB2312-80标准包括了6763个汉字,按其使用频率分为一级汉字3755个和二级汉字3008个。一级汉字按拼音排序,二级汉字按部首排序。该标准还包括标点符号、数种西文字母、图形、数码等符号682个。
区位码的区码和位码采用从01到94的十进制,国标码采用十六进制的21H到73H。区位码和国标码的换算关系是:区码和位码分别加上十进制32。如“国” 字在表中的25行90列,其区位码为2590。国标码是397AH。
2.字形存储码
字形存储码是指供计算机输出汉字(显示或打印)用的二进制信息,也称子模。通常,采用的数字化点阵字模。
一般的点阵规模有1616、2424等。每一个点在存储器中用一个二进制位(bit)存储。在1616的点阵中,需832bit的存储空间,每8bit为1字节,所以,需32字节的存储空间。在相同点阵中,不管其笔画繁琐,每个汉字所长空间所占字节数相等。
例如:在24*24点阵的字库中,汉字“一“ 与 “魏”的字模占用的字节数分别是( 72,72)
解析:2424点阵的字模需要2424个二进制来存储。每个字节有8个二进制位。所以汉字字模占用字节数24*24/8=72个字节。汉字 “一”和“魏”简繁不一样,但所需空间是一样的。
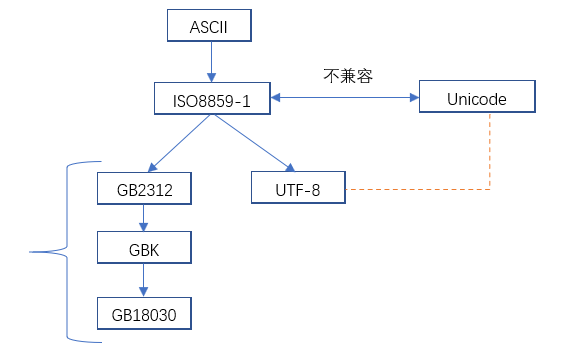
六、编码之间的关系
评论区